
In the past, software was built as a single application and tightly coupled together. As software sales or gets more and more concurrent users or larger volumes of data, things have to change. Either bigger hardware has to be purchased or eventually, you need to spread the load to more machines.
When software is tightly coupled this isn’t possible. We need to design our system to handle scale and to do this it usually makes sense to use patterns.
An architectural pattern is a proven way of organizing and building a software system.
Layered Architecture / n-Tier
The Layed Architecture Pattern or “n-Tier architecture” pattern is pretty commonly used especially in smaller projects that will only have one front-end.
Software is arranged in different layers that have a unique purpose. Examples of the layers might be Presentation Layer, Business Layer, Data Access Layer, Persistence or Database Layer. Each layer communicates linearly – meaning it can only talk to the layer above it or below it. It can’t skip a layer.
The Layered Architecture (or n-Tier) has a number of advantages that allow it to scale pretty well.
- Separate layers or tiers can scale without touching other layers
- Each layer can be secured separately or in different ways.
- Each layer can be individually managed which allows us to isolate maintenance.
The post Introduction to the Layered Architecture (n-Tier Architecture) has a lot more details on the n-Tier architecture.
Client Server Pattern
The Client Server Pattern is a distributed architecture that allows us to partition workloads between the providers of the service (servers!) and service requestors called clients.
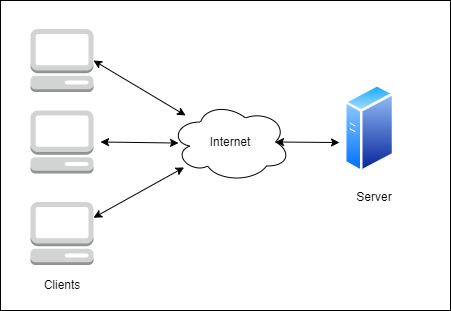
It’s best used when security aspects are an important part of the problem, and when multiple users need to access common information and common applications.
The client server pattern is usually used best when there’s a need for a cohesive end-to-end process that all users need to use and access. For the most part, everything needs to be centralized on a server.
Pipe Filter
The Pipe Filter architecture is commonly used in data engineering or when buffering or synchronization need to be done. Data is processed and filtered and then passed through different filters.
The filters perform different transformations on the data as it is passes through it. The pipes are simply connectors of the data as it streams through to the next filter or process. There’s a few advantages of the pipe filter architecture:
- Loose and flexible coupling is possible between components and filters
- filters can be changed without making modifications to other filters
- filters can be treated as black boxes allowing the users of the system to not necessarily understand all of the works between each filter
A popular example of the pipe filter to developers would be a compiler or the Linux or Unix Shell. In a compiler each step of the compilation process is dependent on the next but doesn’t necessarily know what’s happening in each step.
Model View Controller (MVC)
The Model-View-Controller is an architectural pattern that splits an application into three components – the model, view, and the controller. Each of these components are designed for specific tasks.
- Model – is the business logic and data.
- View – displays the information to the user (usually it’s a combination of HTML, and JavaScript)
- Controller – handles the input from the user.
Many web frameworks like Django, Rails, and Modx use variations of the Model View controller pattern. MVC is the defacto standard for developing web based applications.
Microservices Architecture
The Microservice architecture can make a lot of sense for large applications that have a lot of usage and have a large team working on them. The microservice architecture makes the most sense when you have some of these goals:
- Increasing Release Speed: smaller services are easier to deploy because less things need to be tested.
- Reducing Cost: microservices can be a lot easier to design, implement and maintain.
- Improved Visibility or Resilience: when something is broken it becomes easier to report on it and scale it up when load is higher.
Microservices are usually done at the API level by placing a gateway in front that handles routing requests to the right service. It does this by looking at the paths and routing it to the correct service.
Each Microservice should be independent of the others and ideally have it’s own database and be able to be deployed at any time.

Master Slave Pattern
The Master Slave pattern is commonly used for databases because the master component has the final results. The slaves are identical and will service many requests resulting in the load being spread and more requests being able to be handled at a time.
The blog post Introduction to Relational Database Scaling covers this in quite a bit of detail.
Peer to Peer Pattern
In a peer to peer system a peer can act as a client, as a server or as both. It can dynamically change based on time and on requests. Often there’s “super peers” in the middle that coordinate connecting the different peers together.
The peer to peer pattern is very common in file-sharing networks (Bittorrent, Gnutella, etc) and within quite a few multimedia protocols (P2PTV, PDTP), and more recently some of the cryptocurrency and blockchain applications.
Broker Pattern
The Broker Pattern is designed to decouple components.
Servers publish their capabilities to a Broker which is responsible for routing requests from the client to an appropriate server. The broker coordinates requests and responses between clients and servers. The broker sends the response back to the clients.
There’s a few different systems that do this:
- Apache ActiveMQ
- Apache Kafka
- RabbitMQ
Event Bus Pattern (Enterprise Service Bus)
The Event Bus Pattern allows us to decouple a primary action and a secondary action in the Command Bus pattern. You may have heard of it previously as an Enterprise Service Bus, or a Publisher/Subscriber pattern.
It works by:
- Event Publisher sending “Events” to the Event Bus.
- The Event Bus receives the Events and sends them off to the Event Subscribers.
- The Event Subscribers receive the Event and start to react to it.
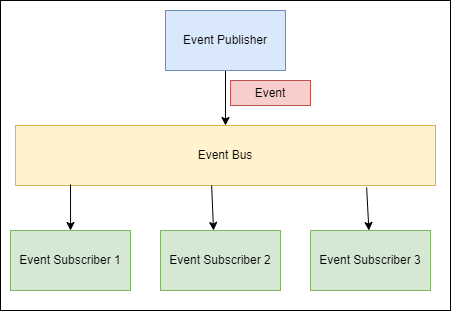
The blog article What is an Enterprise Service Bus? covers this pattern in more detail. For the most part, the Event Bus pattern is an instance of the Mediator pattern.
Blackboard Pattern
The Blackboard pattern works by having multiple components have access to the shared data store or blackboard. Each component can produce new data objects that are added to the blackboard. Components look for data by doing pattern matching.
The Blackboard Pattern is common for systems that will be doing machine learning or artificial intelligence (speech recognition, optical character recognition, etc).
Wrapping It up
Regardless of which pattern you use, there are always going to be some disadvantages. When looking at patterns it’s important to understand what tradeoffs are being made.
In some cases, we might be able to use multiple patterns together. For example, the MVC pattern might be used within an application that is using the Master-Slave pattern.
Also published on Medium.


")

