
Scaling out a relational database to handle large amounts of data or large amounts of simultaneous transactions can be challenging.
There are a few ways we can scale a relational database:
1. primary-secondary replication (Formerly known as “master-slave replication”
2. primary-primary replication (Formerly known as “master-master replication”
3. sharding
4. federation
5. denormalization
Primary-secondary replication (“master-slave replication”)
This is generally the easiest technique. It involves one database getting all of the writes from the application(s) and then copying them to the secondary servers.
When the application needs to read it uses one of the secondary databases to read from.
With a cloud provider, it’s usually pretty trivial to automatically spin up additional secondary servers which allow for a large number of read operations per second.
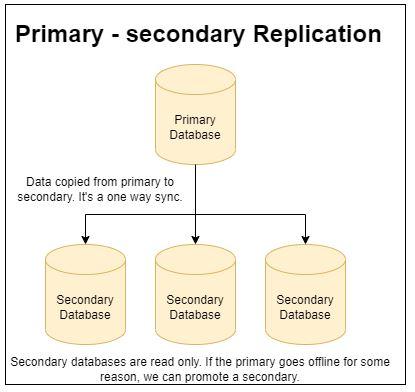
The downfall of primary-secondary replication is that if the primary server goes down for any reason new database updates aren’t possible till a secondary server is promoted to be the primary server.
Additionally, the applications need to have a much smarter data access layer or some sort of infrastructure needs to be added that does the redirecting.
Our application architecture would likely look something like this screenshot. In between our application servers, or web servers, we likely have some code that would decide if we should hit the write server or the read servers.
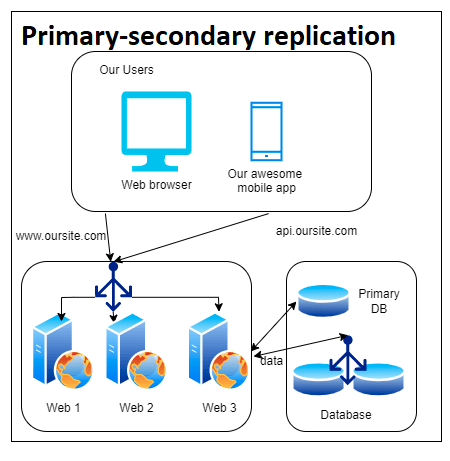
Pro tip: if your company is using a cloud provider like AWS there are database services that can hide this without you necessarily needing to do anything.
In my blog posts, Introduction to Amazon RDS and Introduction to Aurora RDS I explain this in greater detail.
Primary-primary replication (“master-master replication”)
With primary-primary replication, each database server acts as the primary server. All of the servers need to sync to make sure that they have the same data.
The biggest challenge with primary-primary replication is that right from the start the database must have primary keys that are uniquely generated strings.
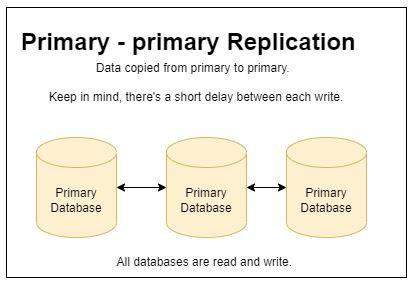
Additionally, all of the databases need to be online and connected to one another or it’s possible to have missing data.
Sharding
Sharding is a way of partitioning the data to break it into smaller databases that only have a subset of the data.
Essentially we would try to have all of the data a particular user ever needs on the same database and the load would be equally balanced between all of the various databases.
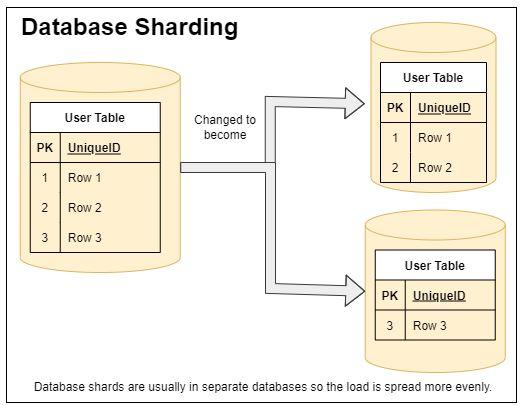
Sharding is a great way of also doing horizontal scaling as it allows us to spread out the load and allow for more traffic. Sharding is commonly done as a way to speed up query response times because the database engine won’t necessarily need to scan every row in the table.
Federation
The concept is that the database is split up by functions or maybe years of data if transactions. If we had an application for a school we might have separate databases for courses, teachers, and students.
Federation is really common for microservices, but comes with a potential cost. We must do multiple database queries to different databases whenever we need to do joins on multiple tables.
Alternatively, the federation could happen on something like the years of data. This is commonly done by banks and others to avoid having billions or trillions of database records.
Denormalization
Database denormalization tries to improve read performance by moving the expense to create/update operations.
It works by doing the opposite of normalization. Copies of data might be in multiple database tables, or data might be consistently replicated in tables to try and avoid doing joins. Joins are one of the number causes of poor database performance.
This is usually a worthwhile trade-off because database reads usually outnumber writes by 100:1 or even higher.
Wrapping It up
Scaling relational databases can be hard especially if you don’t take the time upfront to prepare for it. If you are using an open source database and are hosted on a cloud provider like AWS it can be a lot easier.
It’s definitely not without challenges though.



