I have worked quite a bit with AWS Lambda and the Serverless Framework since 2015. I have worked on seven fairly large projects that either started on AWS Lambda or moved to AWS Lambda after reviewing the usage and architecture.
Logging is very important to developers as it helps us more efficiently debug a system in production and the steps that led to the occurrence of the bug. For an application that has many different microservice or many different functions, logging becomes very important.
Logging in AWS Lambda is very simple. Any printed message is logged in the CloudWatch logs which can result in some very big bills in a short period of time. Reducing logging so you don’t end up with very large bills can be challenging, so that’s why I’ve put together this blog article of what I consider to be best practices.
Set Logging Levels
One of the things you generally learn early on in software development is the value of setting different logging levels, so you can easily ignore noise on production but still have a good idea what is going on during development. Logging levels are a piece of metadata that allow us to see the importance of something – like a system outage to maybe calling a deprecated function.
Most logging libraries allow us to set a severity level, usually things like Debug, Info, Warn or Error. Logging libraries that support levels won’t write to the logs if you set the severity to something like Debug unless it’s a Warning or an Error.
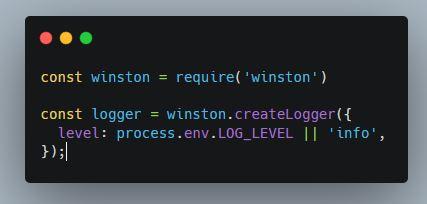
I like to use the logging library winston when I do logging in Node.js, I haven’t found a case yet where I haven’t been able to have something work the way would expect.
Log Just Enough
Per gigabyte of data the cost to use CloudWatch is $0.50. There’s a free tier, but it only covers the first 5gb. With a function called a few times a second, it’s very easy to hit $10 to $15 a month in costs. Obviously the more you log, the higher the costs get.
As we add a logger, the first question we should be asking ourselves is “Do I need to log anything?”. In development, it might make sense to log a lot more than in production. Every time we log something to CloudWatch about 70 bytes of metadata are added (timestamp, and request ID).
There is also a cost to storing the data every month.
Set Log Retention
Retaining data in CloudWatch is approximately $0.03 per gigabyte which adds up pretty quickly if we never remove any data.
Secondly, it’s possible that confidential data that shouldn’t have been logged is logged in the database. By removing data regularly and on a cycle the odds of confidential data causing damage is minimized.
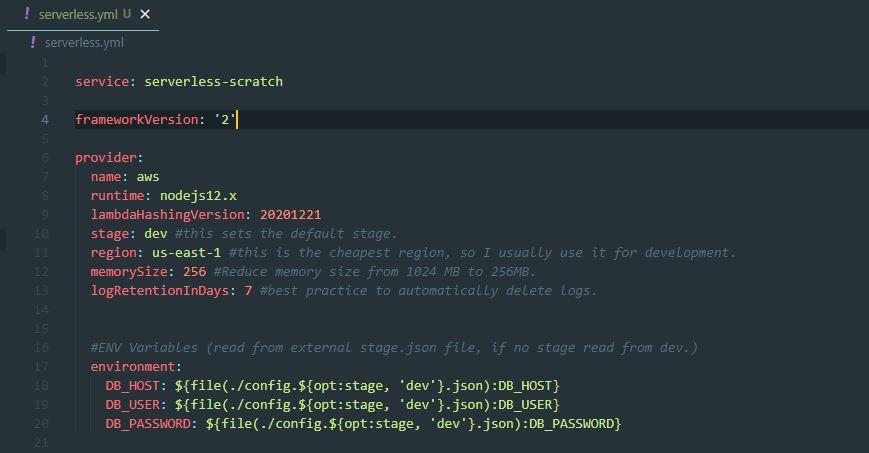
Fortunately, there’s a way to have CloudWatch automatically remove logs that are older than 30 days. In serverless.yml, we can set the logRetentionInDays under the provider section.
A Simple Logging Middleware
Like mentioned previously, I like to use the winston logging library as a base for my logging. I find it works very well and can be used for logging on EC2 – and still write to CloudWatch. That’s a huge win in my mind.
I try to reduce my logging noise so errors are obvious and easy to walk through. Part of how I reduce the logging noise is a logging level in my environment variables.
In Production, I don’t generally log very much. In development I log everything.

Wrapping It Up
The most important thing with AWS Lambda and CloudWatch is reducing the noise which helps reduce the cost. I highly recommend using winston and setting a default logging level using an environment variable.


")
